





文:記者王蔚
2022年年尾,聊天機器人ChatGPT橫空出世,成為2023年炙手可熱的話題。它的主人OpenAI公司因此名聲大噪,被看作前沿潮流科技的符號。該公司的創始人之一、CEO Sam Altman被譽為ChatGPT之父,成為科技界明星。但是11月17日Altman突遭OpenAI董事會罷免,旋即掀起輿論風暴。然而戲劇化的是,三天後他又官復原位。業界和媒體紛紛猜測「宮鬥」大戲背後的玄機,有人分析,這與OpenAI秘密開發的Q*有關。
Q*帶來人工通用智能突破
11月23日路透社的一篇報道披露,OpenAI的神秘項目Q*取得了突破性進展,它能像人腦一樣,進行有邏輯的思考,還能做簡單的數學演算。Q*究竟在哪些領域能夠挑戰甚至超過人類的智能?
獲得卡內基梅隆大學電腦和機器人專業博士的鄧侃,曾擔任百度資深技術總監,後來創辦人工智能醫療平台。他分析,OpenAI沒有發表相關論文談到Q*,但人們可以研讀OpenAI以往的論文及關聯信息來分析推測,Q*的關鍵是Q-learning、RLHF、A*等算法,它的突破涉及AI大模型要解決的4個問題。一是理解能力要強,能聽懂人話、看懂圖像。二是知識要淵博,能夠接取私域數據,補充最新知識,自主尋找有用知識,即「自學成才」。三要思路清晰,既想像力開闊,又邏輯嚴謹。四要表達能力強,說得出人話,寫得出程式和公式,畫得出圖像和影片。
他說,GPT在3.5版本以前,生成內容時主要靠詞語接龍來完成。例如,前半句是「我愛北京」,後半句大概率是「天安門」,合在一起是「我愛北京天安門」 。但也可能合成為「我愛北京中關村」, 「這就造成了生成內容時存在不確定性,這個不確定性就造成了GPT胡言亂語(hallucination)的現象。」
如何才能讓AI大模型,遵循預設的思路去產生內容呢?鄧侃說,2022年初,Google的幾位華裔研究員發表了一篇重要的論文,提出Chain of Thoughts的概念,輸入給大模型的不僅包含問題,而且也包含成功案例。「讓AI大模型,照貓畫虎模仿榜樣,解決新問題,而且要說推理的過程,也就是思路。」。
硅谷AI、機器人、半導體光刻技術專家龐琳勇博士說,看過Q*的人感到它更像人的智能了。Q*包含Q-learning和A*,Q-learning是加強學習,如AlphaGo就是。加強學習就是,比如走一步離目標近了,就再往下走;離目標遠了就知道不對,那就調整方向。A*技術起源於1968年史丹福學者做移動機器人,Q*把它跟深度神經網絡的加強學習相結合,現在與大語言模型結合起來,想到了人所沒有辦法想到的一種數學,即解開網站、加密貨幣等使用的「加密」。「加密」本來是很難解的,128位加密用超級計算機要算幾萬年才能解密,而現在Q*一下子就能解開。所以OpenAI董事會看了大為震驚,「他們認為這樣放出去可能把整個人類社會都毀滅了。可以想見,人們的銀行信息、比特幣、數字貨幣等等可能一下子就被人破壞了。」這也是董事會一些人對Q*的推出持保守態度的原因之一。
矽谷人工智能專家、亞馬遜高級研發經理周涵寧認為,強化學習有兩種路徑,一是摸著石頭過河,如進入黑房子往前摸著走,碰到牆就後退。另一種就是Q-learning,每摸一塊石頭就會紀錄,最終這個機器人就會構建一幅地圖,下次每走一步都會自我衡量批判,這樣算法效率提高很多。這首先用在數學證明上,因為數學有很多正樣本能夠證明對錯,非黑即白,不需要主觀判斷,而之前強化學習的很多問題都需要人的判斷,涉及到價值觀的東西,很難說清楚。「目前公開資料唯一已經確定的就是,Q*對數學證明有一個飛躍,因此用在加密的解密上也有道理。」
大模型的未來 媲美人類大腦
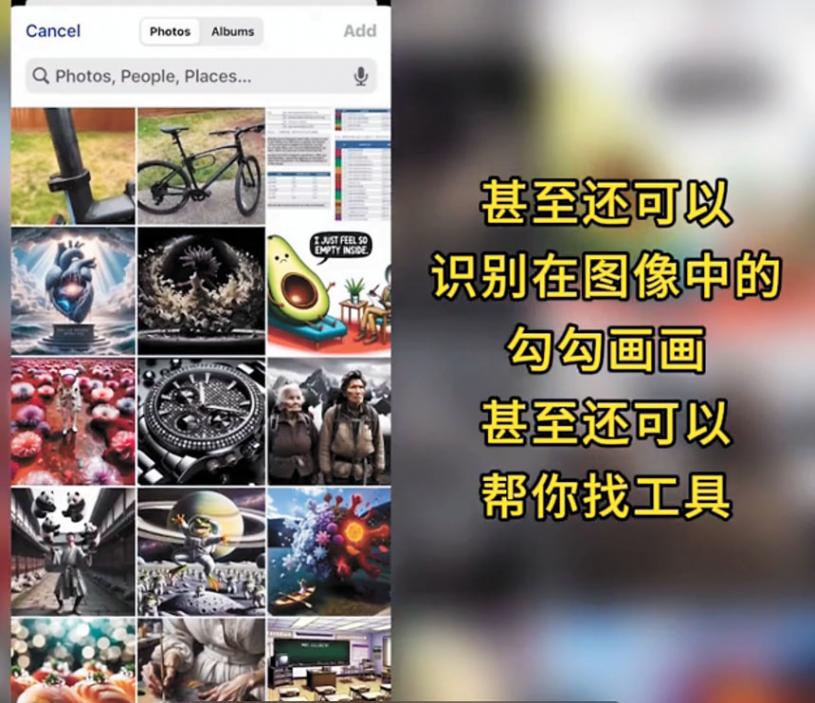
2023年9月末,OpenAI的兩項成果引人注目,一個是語音對話,能夠模仿人類換氣和語調詞,讓人難以分辨是機器還是人在說話。另一個是GPT4V,圖文並茂地對話,可以讓GPT指導人修自行車,找工具等。
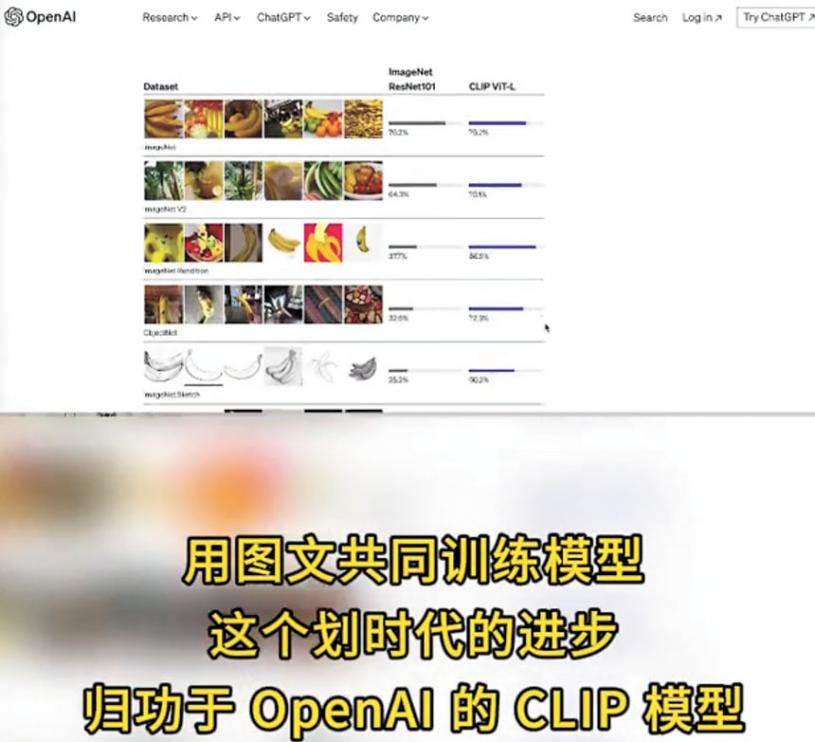
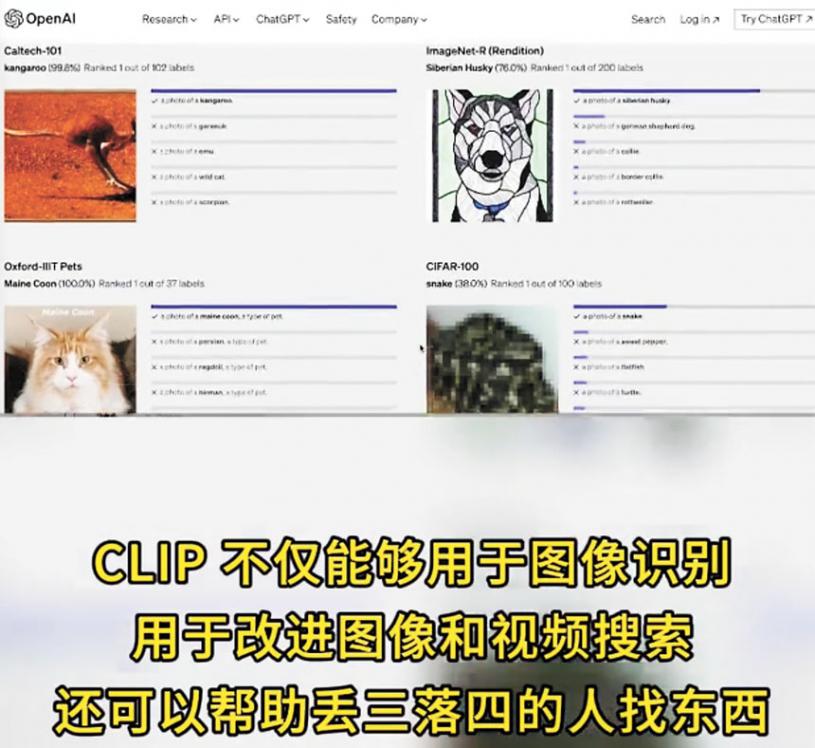
鄧侃認為,CLIP模型是劃時代的進步,人類第一次讓機器能理解影像和視訊的語意內涵。這不僅改進了影像辨識和搜尋的精確度,還可以幫助人們找回遺失的物件等等,深入介入人類生活。「圖像文字語音三位一體的多模態大模型,讓人工智能越來越接近人類智慧了。」
鄧侃說,大模型的未來理想狀態,是達到媲美人類大腦的能力。 「以GPT 為代表的大模型,不僅能夠聽得懂人話,說得出人話,而且現在已經基本上看得懂照片和視頻了,這是大模型感知能力的提升。」接下去,隨著大模型生成能力的提升,還能寫文字、做照片、譜曲、製作視頻。再進一步,「是記得住知識,想得清邏輯,這是大模型認知能力的提升。」
曾在必應搜索、微軟研究院等部門工作的人工智能專家胡宇曉博士認為,大模型的近期和中期發展,從技術上來說主要是實用化。使模型更小(減少記憶體需求,可以運行在手機等終端設備上),更快(減少算力需求,可以降低運維成本),更準(減少輸出的錯誤和幻覺)。從應用領域上看未來大模型覆蓋面會更廣,能輔助藥物開發、生物實驗、計算化學、材料設計、數學計算、定理證明等各方面的研發。與其他軟體和數據配合,能實現自動編程、客服、教育、諮詢等等;與其他硬體和感測器配合,可實現機器人、自動駕駛等。
鄧侃設想,普通人可以在大模型訓練中受益。「能不能把MoE系統架構從一個公司的機房裡解放出來,讓千千萬萬普通老百姓也能參與Mistral的大模型訓練?」 也即一般人不只是大模型的消費者,也是生產者。例如Google、百度這樣的搜尋引擎,用的人越多,搜尋結果越準。「或許將來,一般人使用大模型,不但不要付錢,還可能會獲得利益。」
未來AI博弈 誰執牛耳?
目前Apple、Google、Amazon、Meta、微軟等多家巨頭公司都在AI前沿厲兵秣馬、你追我趕, OpenAI會繼續佔據優勢嗎?未來主要集中在哪幾家之間進行博弈?
鄧侃認為,或許將來會出現三個陣營,一是微軟/OpenAI為代表的大廠陣營,OpenAI將逐漸淡出舞台中央,讓位於微軟這樣的大廠,能夠與微軟分庭抗禮的,將是Google。二是Meta助力的開源陣營,包括Mistral、Huggingface等等一眾小廠,Nvidia也很有可能加入開源。三是Apple為代表的應用陣營,Apple發力點將是快速穩定地落地到手機應用,Adobe也強調應用落地,Tesla側重於人形機器人。
胡宇曉認為,演算法方面OpenAI暫時領先,但優勢不大,大概半年到一年;數據方面,Google有網頁數據,OpenAI/微軟有對話和業務數據,蘋果有行動裝置數據,當然它們的覆蓋率也有交叉;算力方面,大家既依賴Nvidia的GPU(Google有TPU),也都有自己的晶片發展計畫。「所以這幾家都會是長期主流玩家。」未來競爭的核心主要會集中在數據方面,誰能拿到與目標領域更相關、更多、更乾淨的數據,誰就會有先發優勢,也能吸引到更多的人才。因此,「我還要特別提出特斯拉和亞馬遜,它們目前經營的駕駛/購物/居家等場景,是前面提及的公共數據之外,其他玩家比較難得到的。」
龐琳勇認為,OpenAI至少比其他競爭對手領先一至一年半。
AI風險和危險如何防範
英偉達的老闆黃仁勳2023年11月份在紐約的一個論壇上說到,未來五年內,AGI將會達到與人的智能進行相當競爭的階段。人工智能目前在哪些領域超越了人類智慧?未來哪些領域AI是無法取代人智的?
鄧侃說,AI比人強的方面有,知識記憶的廣度和生成相似內容的速度遠超人類。 AI不如人類的方面是,更有效地記憶知識,從而獲得舉一反三的學習能力,有章可循的思考,有明確邏輯的推理。
周涵寧說,目前,OpenAI在有固定答案、確定對錯的任務上,如SAT、法律考試等都已經超過人類。但可能難的是在那些有主觀價值觀的東西, 取決於人類的判斷,AI很難猜出來。
當超級人工智能能夠媲美人腦甚至超越人類智慧時,安全、危險、風險問題如何掌控?如何防止先進技術被不法分子用於犯罪?
鄧侃指出,不要教AI破解密碼,一旦它會破解密碼,它可能會偷銀行。另外不要教AI感情,寧可低情商,也不能讓它學會操縱人類的情感。
矽谷矽物聯網、大數據、人工智能專家蔣志予博士指出,任何新技術都不是技術本身帶來危險,而是我們怎麼利用。核能帶來了核武器也帶來了核電站,核武有殺傷力、核能是造福人類的。安全問題取決於技術本身的發展,也取決於我們怎樣制定政策和法律法規來規範和指導,也需要證明的過程,不是理論上就能預測未來的發現的。
周涵寧認為,防範危險需要法律的限制,但掌控風險的不一定是僅僅靠條約和規定,而是如博弈論,更多的是彼此摧毀的危險帶來各方的制衡,就像核武控制一樣。









